Para los que todavía no lo conocen,
Screaming Frog es una de las herramientas más útiles para auditar un sitio para SEO. Consiste en una aplicación que crawlea un sitio entrando en la URL inicial y luego en cada uno de sus links hasta haber leído al sitio entero. El resultado es una cantidad de información muy valiosa acerca del sitio, ya sean URLs, páginas con errores, redirecciones, títulos, meta data, etc.
Al igual que toda herramienta, hay gente que solamente la utiliza para fines básicos sin saber que existe mucho jugo que se le puede extraer. En el post de hoy, te vamos a mostrar cómo podés analizar la
estrategia de linking interno de tus competidores. Como consecuencia, vas a poder tomar los insights extraídos del crawleo para poder optimizar tu propia estrategia de links internos acorde.
Para poder lograr esto, vamos a extraer los anchor texts de los enlaces internos de un sitio. Cabe destacar que existen formas más fáciles de hacer esto con
Screaming Frog... no obstante, hoy te vamos a mostrar un método un poco más avanzado que además se puede utilizar para
leer todas las etiquetas HTML que existen en una página.
Nuestro objetivo es levantar data del código fuente de una o varias páginas. Esta práctica también se conoce como
web scraping. Recordá moverte dentro de lo permitido en los términos y condiciones del sitio siempre que estés leyendo su código fuente utilizando una aplicación.
¡Empecemos! Dentro del Screaming Frog, vamos a ir al menú Configuration > Custom > Extraction. Esta sección te permite extraer data del código fuente de las páginas que crawleas. Si estás usando una versión gratuita de SF, esta opción va a estar deshabilitada. Recomendamos invertir en una versión completa si es que regularmente trabajás haciendo auditorías SEO.
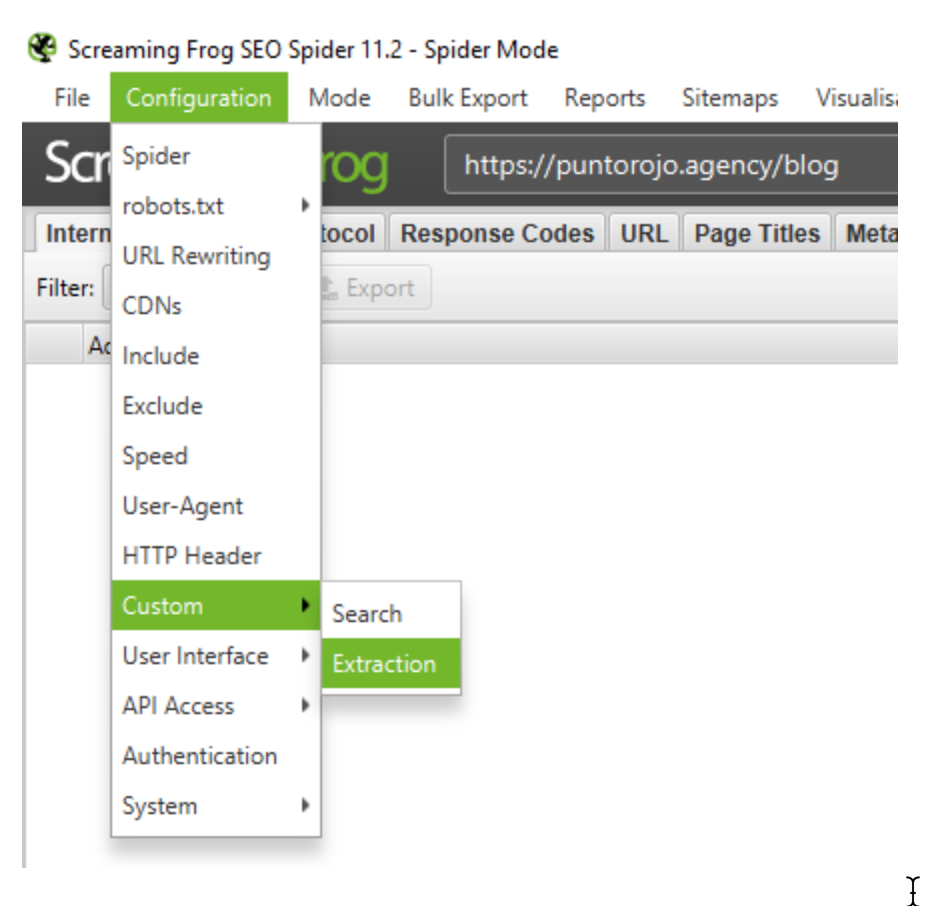
Anchor text benchmarking
El benchmarking es una práctica basada en analizar cómo se comporta tu competencia para poder ajustar tu estrategia según lo aprendido. En el caso de hoy, vamos a estudiar los anchor texts o textos de anclaje de los enlaces internos. Para hacer esto, va a hacer falta configurar la siguiente expresión regular (regex, para los amigos) en el menú custom > extraction:
<a.*?>(.*?)<\/a>

Este snippet levanta todo lo que esté dentro de tags <a> y se lee de la siguiente forma:
Capturá todos los caracteres que hayan dentro de cada etiqueta <a> sin importar los atributos html de la misma y frená la captura cuando se cierre la etiqueta. Si todavía no estás muy familarizado on Regex, te recomendamos investigar un poco el tema online.
Regex no es la única forma de extraer información de un texto. Existen otros métodos como XPath que trabajan un poco más con el DOM (Document Object Model) de la página. A continuación detallamos el snippet para levantar todas las etiquetas <a> con XPath.
//a
Asegurarse de que esté seleccionada la opción “XPath” y “Extract Text” para que extraiga únicamente el texto y nada más ya que algunos links están asociados a etiquetas de imágenes.

Ya sea que usemos una Regular Expression o el XPath, una vez que esté configurado corremos el crawler para que se comience a levantar cada anchor text de cada link dentro de cada página que se lee.
Una vez corrido el crawl, para ver los resultados sólo tenemos que fijarnos en la solapa “Custom” y luego elegir “Extraction” del dropdown.
 Notar que además del item ‘extraction’ existen varios filtros adicionales. Si se configura más de un filtro, cada uno de ellos va a figurar en su propio item del dropdown. Como sólo usamos el menú de extracción, seleccionamos el último elemento de la lista.
¡Y listo! Vemos que el Screaming levantó todas las etiquetas de anclaje de los links. Esta data se puede exportar a CSV haciendo click en el botón de ‘Export’.
Notar que además del item ‘extraction’ existen varios filtros adicionales. Si se configura más de un filtro, cada uno de ellos va a figurar en su propio item del dropdown. Como sólo usamos el menú de extracción, seleccionamos el último elemento de la lista.
¡Y listo! Vemos que el Screaming levantó todas las etiquetas de anclaje de los links. Esta data se puede exportar a CSV haciendo click en el botón de ‘Export’.
 Otro método similar a este es analizar los enlaces de los links en lugar de los textos de anclaje. Para lograr esto sólo tenemos que correr el siguiente filtro de extracción customizado Regex en Screaming Frog:
Otro método similar a este es analizar los enlaces de los links en lugar de los textos de anclaje. Para lograr esto sólo tenemos que correr el siguiente filtro de extracción customizado Regex en Screaming Frog:
href=”(.*?)”
Estos son sólo un par de ejemplos de escrapeos que se pueden realizar. Puede que tengas que scrapear otros elementos como etiquetas de encabezado h3, spans, divs ocultos, etiquetas HTML personalizadas, etc.
Cómo graficar los resultados
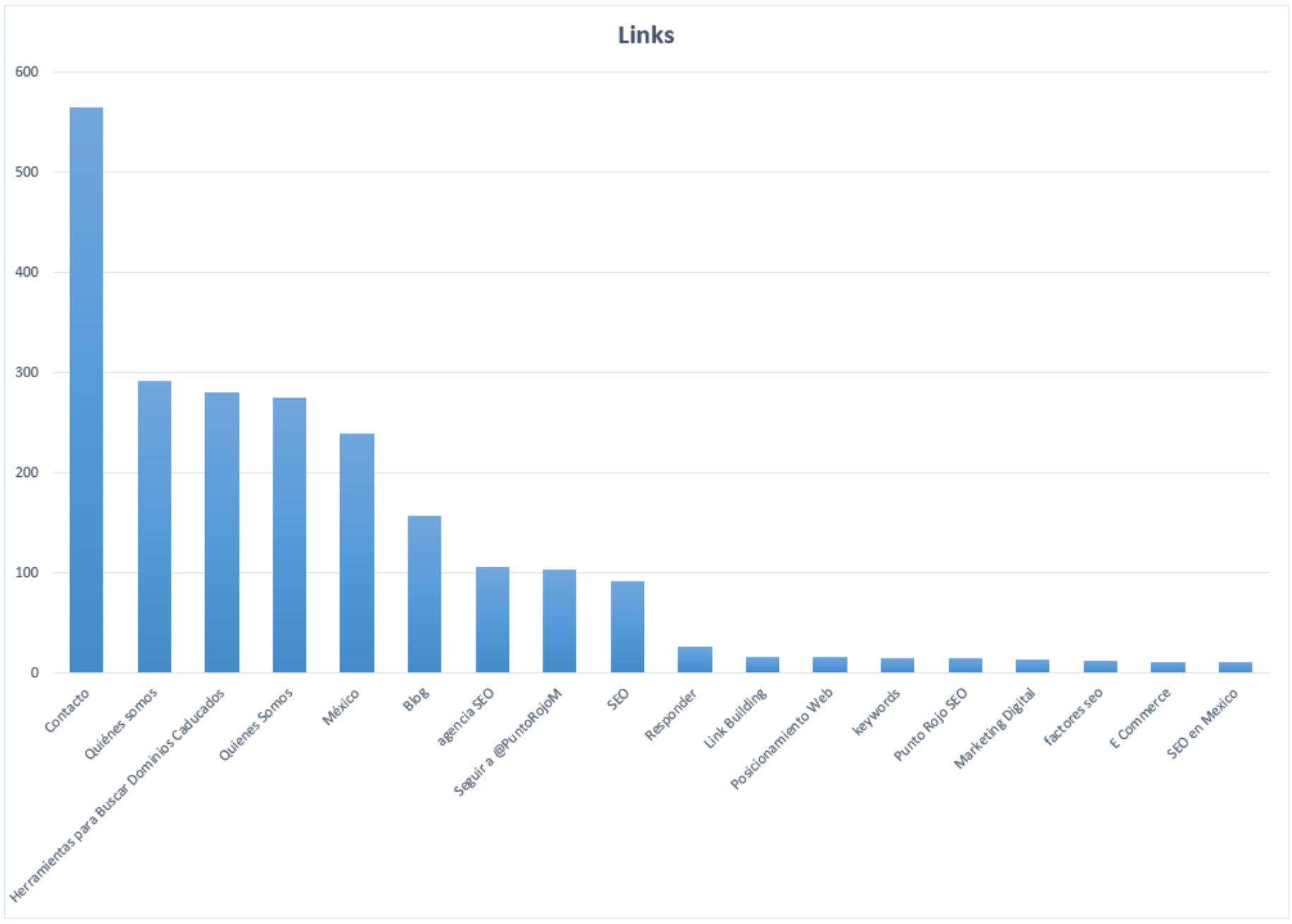
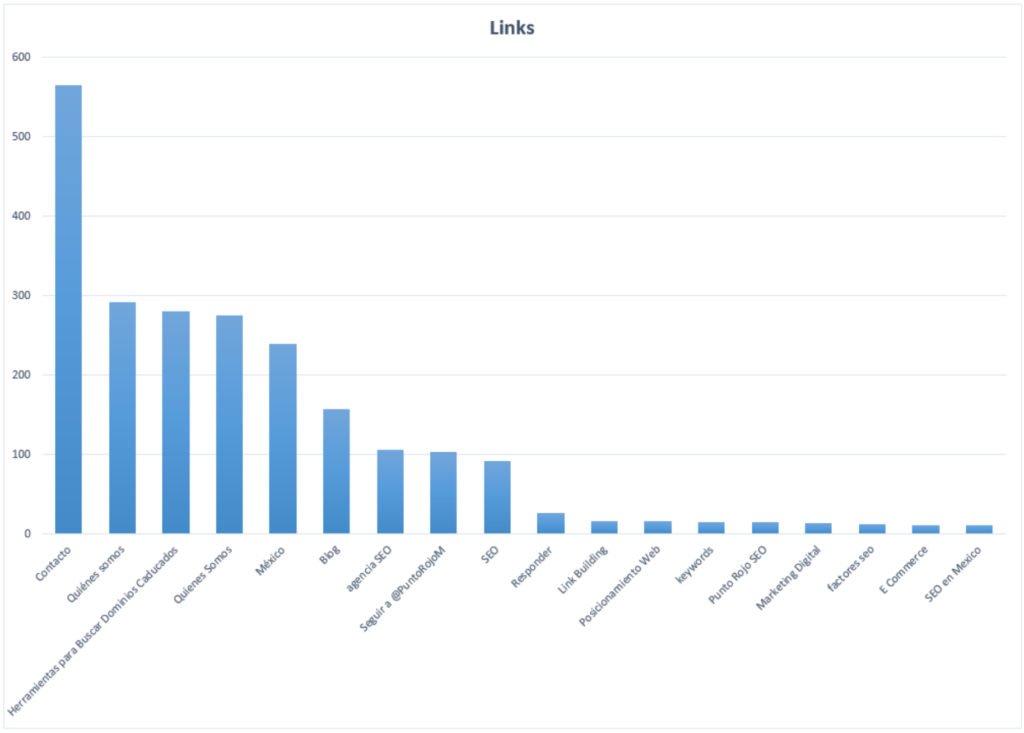
Ya tenemos la data, ahora veamos qué insights nacen de ella. Si pasamos el CSV que exportamos a una hoja de cálculos y lo limpiamos un poco podemos armar un gráfico con la cantidad de anchors que más se repiten.
Gráfico de los anchor text más repetidos en nuestro crawleo
 Para armar un gráfico similar a este, sólo tenés que seguir los siguientes pasos:
1.Dentro de una hoja de cálculos, listar en una única columna todas las keywords que se levantaron. Es probable que varios valores figuren más de una vez ya que puede existir más de un link con el mismo anchor text.
2. Copiar la columna y pegarla en la columna de al lado.
Para armar un gráfico similar a este, sólo tenés que seguir los siguientes pasos:
1.Dentro de una hoja de cálculos, listar en una única columna todas las keywords que se levantaron. Es probable que varios valores figuren más de una vez ya que puede existir más de un link con el mismo anchor text.
2. Copiar la columna y pegarla en la columna de al lado.
3. Seleccionar la columna y eliminar los duplicados.Si estás usando Microsoft Excel, podés ir al menú de Datos > Quitar duplicados.
 Si estás usando Google Sheets, es probable que tengas que descargar un plugin para eliminar los valores duplicados. Existen formas de eliminar duplicados en Google Sheets sin usar un plugin, pero cae fuera del alcance de este post.
4. En este momento tenemos todos los términos en una columna y luego todos los términos sin duplicados en la columna de al lado.
5. Con una simple función de CONTAR.SI* podemos encontrar cuántas veces se repite un término único en el listado de todos los términos.
6. Paso final, graficamos la data para obtener un gráfico similar al de arriba.
*La sintaxis de la fórmula es =CONTAR.SI(rango_con_duplicados; keyword_a_buscar)
Si estás usando Google Sheets, es probable que tengas que descargar un plugin para eliminar los valores duplicados. Existen formas de eliminar duplicados en Google Sheets sin usar un plugin, pero cae fuera del alcance de este post.
4. En este momento tenemos todos los términos en una columna y luego todos los términos sin duplicados en la columna de al lado.
5. Con una simple función de CONTAR.SI* podemos encontrar cuántas veces se repite un término único en el listado de todos los términos.
6. Paso final, graficamos la data para obtener un gráfico similar al de arriba.
*La sintaxis de la fórmula es =CONTAR.SI(rango_con_duplicados; keyword_a_buscar)
Conclusión
Si escarbamos un poco, podemos encontrar funcionalidades avanzadas dentro del Screaming Frog que nos permiten conocer en profundidad qué es lo que más linkea nuestra competencia. Además de esto, se puede obtener gran cantidad de información tanto de sitios competidores como de sitios nuestros.
¿Cuáles son las funcionalidades avanzadas de Screaming Frog que más usás? Contanos dejando un comentario abajo y, como siempre, ¡buenos rankings!